Starting machine “podman-machine-default” Waiting for VM … Mounting volume… /Users:/Users Mounting volume… /private:/private Mounting volume… /var/folders:/var/folders
This machine is currently configured in rootless mode. If your containers require root permissions (e.g. ports < 1024), or if you run into compatibility issues with non-podman clients, you can switch using the following command:
podman machine set --rootful
API forwarding listening on: /Users/Shared/CLOUD/Programmier-Workshops/Kurse/Haskell/.podman/podman.sock
The system helper service is not installed; the default Docker API socket address can’t be used by podman. If you would like to install it run the following commands:
Building a Docker image mainly means creating a Dockefile and specifying all the required components to install and configure.
So a Dockerfile contains at least many operating system commands for installing and configuring software and packages.
Keeping all commands in one file (Dockerfile) can lead to a confusing structure.
In this post I describe and explain an extensible structure for a Docker project so that you can reuse components for other components.
General Structure
The basic idea behind the structure is: split all installation instructions into separate installation scripts and call them individually in the dockerfile.
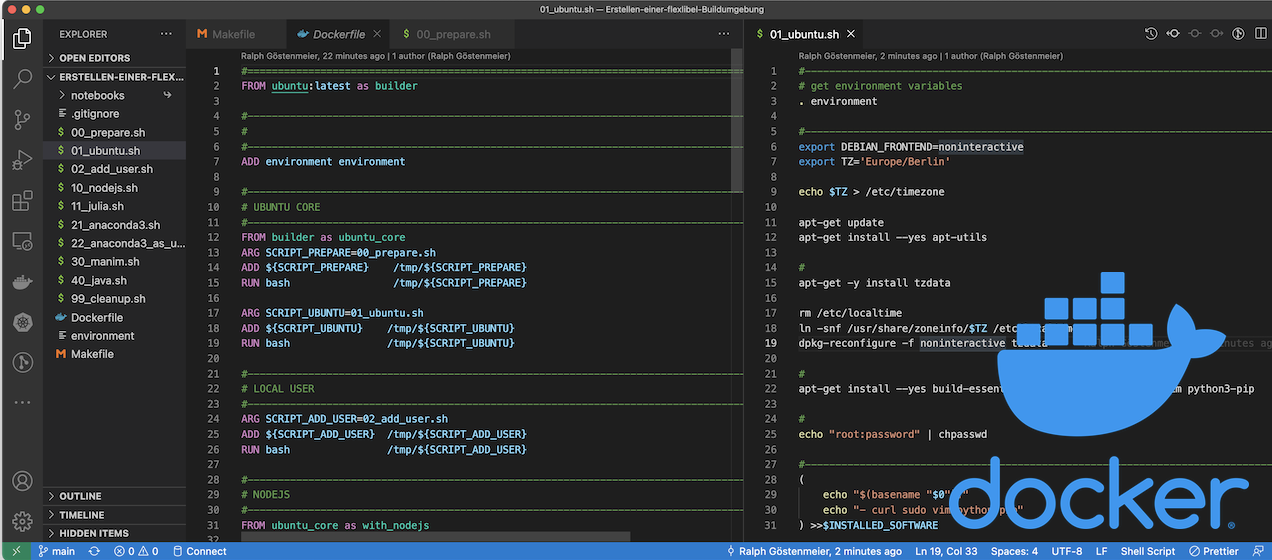
In the end the structure will look something like this (with some additional collaborators to be added and described later)
RUN bash /tmp/${SCRIPT_UBUNTU}
RUN bash /tmp/${SCRIPT_ADD_USER}
RUN bash /tmp/${SCRIPT_NODEJS}
RUN bash /tmp/${SCRIPT_JULIA}
RUN bash /tmp/${SCRIPT_ANACONDA}
RUN cat ${SCRIPT_ANACONDA_USER} | su user
RUN bash /tmp/${SCRIPT_CLEANUP}
For example, preparing the Ubuntu image by installing basic commands is transfered into the script 01_ubuntu_sh
Hint: There are hardly any restrictions on the choice of names (variables and files/scripts). For the scripts, I use numbering to express order.
Since we will be working with several scripts, an exchange of information is necessary. For example, one script installs a package and the other needs the installation folder.
We will therefore store information needed by multiple scripts in a separate file: the environment file environment
And each installation script must start with a preamble to use this environment file:
#--------------------------------------------------------------------------------------
# get environment variables
. environment
Preparing Dockerfile and Build Environment
When building an image, Docker needs all files and scripts to run inside the image. Since we created the installation scripts outside of the image, we need to copy them into the image (run run them). This also applies to the environment file environment.
File copying is done by the Docker ADD statement.
First we need our environment file in the image, so let’s copy this:
#======================================================================================
FROM ubuntu:latest as builder
#--------------------------------------------------------------------------------------
ADD environment environment
Each block to install one required software looks like this. To be flexible, we use variable for the script names.
ARG SCRIPT_UBUNTU=01_ubuntu.sh
ADD ${SCRIPT_UBUNTU} /tmp/${SCRIPT_UBUNTU}
RUN bash tmp/${SCRIPT_UBUNTU}
Note: We can’t run the script directly because the run bit may not be set. So we will use bash to run the text file as a script.
As an add-on, we will be using Docker’s multi-stage builds. So here is the final code:
#--------------------------------------------------------------------------------------
# UBUNTU CORE
#--------------------------------------------------------------------------------------
FROM builder as ubuntu_core
ARG SCRIPT_UBUNTU=01_ubuntu.sh
ADD ${SCRIPT_UBUNTU} /tmp/${SCRIPT_UBUNTU}
RUN bash
Final results
Dockerfile
Here is the final Dockerfile:
#==========================================================================================
FROM ubuntu:latest as builder
#------------------------------------------------------------------------------------------
#
#------------------------------------------------------------------------------------------
ADD environment environment
#------------------------------------------------------------------------------------------
# UBUNTU CORE
#------------------------------------------------------------------------------------------
FROM builder as ubuntu_core
ARG SCRIPT_UBUNTU=01_ubuntu.sh
ADD ${SCRIPT_UBUNTU} /tmp/${SCRIPT_UBUNTU}
RUN bash /tmp/${SCRIPT_UBUNTU}
#------------------------------------------------------------------------------------------
# LOCAL USER
#------------------------------------------------------------------------------------------
ARG SCRIPT_ADD_USER=02_add_user.sh
ADD ${SCRIPT_ADD_USER} /tmp/${SCRIPT_ADD_USER}
RUN bash /tmp/${SCRIPT_ADD_USER}
#------------------------------------------------------------------------------------------
# NODEJS
#-----------------------------------------------------------------------------------------
FROM ubuntu_core as with_nodejs
ARG SCRIPT_NODEJS=10_nodejs.sh
ADD ${SCRIPT_NODEJS} /tmp/${SCRIPT_NODEJS}
RUN bash /tmp/${SCRIPT_NODEJS}
#--------------------------------------------------------------------------------------------------
# JULIA
#--------------------------------------------------------------------------------------------------
FROM with_nodejs as with_julia
ARG SCRIPT_JULIA=11_julia.sh
ADD ${SCRIPT_JULIA} /tmp/${SCRIPT_JULIA}
RUN bash /tmp/${SCRIPT_JULIA}
#---------------------------------------------------------------------------------------------
# ANACONDA3 with Julia Extensions
#---------------------------------------------------------------------------------------------
FROM with_julia as with_anaconda
ARG SCRIPT_ANACONDA=21_anaconda3.sh
ADD ${SCRIPT_ANACONDA} /tmp/${SCRIPT_ANACONDA}
RUN bash /tmp/${SCRIPT_ANACONDA}
#---------------------------------------------------------------------------------------------
#
#---------------------------------------------------------------------------------------------
FROM with_anaconda as with_anaconda_user
ARG SCRIPT_ANACONDA_USER=22_anaconda3_as_user.sh
ADD ${SCRIPT_ANACONDA_USER} /tmp/${SCRIPT_ANACONDA_USER}
#RUN cat ${SCRIPT_ANACONDA_USER} | su user
#---------------------------------------------------------------------------------------------
#
#---------------------------------------------------------------------------------------------
FROM with_anaconda_user as with_cleanup
ARG SCRIPT_CLEANUP=99_cleanup.sh
ADD ${SCRIPT_CLEANUP} /tmp/${SCRIPT_CLEANUP}
RUN bash /tmp/${SCRIPT_CLEANUP}
#=============================================================================================
USER user
WORKDIR /home/user
#
CMD ["bash"]
source < (kubectl completion bash) # setup autocomplete in bash into the current shell, bash-completion package should be installed first.
echo "source <(kubectl completion bash)" >> ~/.bashrc
You can also use a shorthand alias for kubectl that also works with completion:
alias k=kubectl
complete -F __start_kubectl k
ZSH
source <(kubectl completion zsh) # setup autocomplete in zsh into the current shell
echo "[[ $commands[kubectl] ]] && source <(kubectl completion zsh)" >> ~/.zshrc # add autocomplete permanently to your zsh shell
Kubectl context and configuration
Set which Kubernetes cluster kubectl communicates with and modifies configuration information. See Authenticating Across Clusters with kubeconfig documentation for detailed config file information.
kubectl config view # Show Merged kubeconfig settings.
# use multiple kubeconfig files at the same time and view merged config
KUBECONFIG=~/.kube/config:~/.kube/kubconfig2
kubectl config view
# get the password for the e2e user
kubectl config view -o jsonpath='{.users[?(@.name == "e2e")].user.password}'
kubectl config view -o jsonpath='{.users[].name}' # display the first user
kubectl config view -o jsonpath='{.users[*].name}' # get a list of users
kubectl config get-contexts # display list of contexts
kubectl config current-context # display the current-context
kubectl config use-context my-cluster-name # set the default context to my-cluster-name
# add a new user to your kubeconf that supports basic auth
kubectl config set-credentials kubeuser/foo.kubernetes.com --username=kubeuser --password=kubepassword
# permanently save the namespace for all subsequent kubectl commands in that context.
kubectl config set-context --current --namespace=ggckad-s2
# set a context utilizing a specific username and namespace.
kubectl config set-context gce --user=cluster-admin --namespace=foo
&& kubectl config use-context gce
kubectl config unset users.foo # delete user foo
Kubectl apply
apply manages applications through files defining Kubernetes resources. It creates and updates resources in a cluster through running kubectl apply. This is the recommended way of managing Kubernetes applications on production. See Kubectl Book.
Creating objects
Kubernetes manifests can be defined in YAML or JSON. The file extension .yaml, .yml, and .json can be used.
kubectl apply -f ./my-manifest.yaml # create resource(s)
kubectl apply -f ./my1.yaml -f ./my2.yaml # create from multiple files
kubectl apply -f ./dir # create resource(s) in all manifest files in dir
kubectl apply -f https://git.io/vPieo # create resource(s) from url
kubectl create deployment nginx --image=nginx # start a single instance of nginx
# create a Job which prints "Hello World"
kubectl create job hello --image=busybox -- echo "Hello World"
# create a CronJob that prints "Hello World" every minute
kubectl create cronjob hello --image=busybox --schedule="*/1 * * * *" -- echo "Hello World"
kubectl explain pods # get the documentation for pod manifests
# Create multiple YAML objects from stdin
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-sleep
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
---
apiVersion: v1
kind: Pod
metadata:
name: busybox-sleep-less
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000"
EOF
# Create a secret with several keys
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
password: $(echo -n "s33msi4" | base64 -w0)
username: $(echo -n "jane" | base64 -w0)
EOF
Viewing, finding resources
# Get commands with basic output
kubectl get services # List all services in the namespace
kubectl get pods --all-namespaces # List all pods in all namespaces
kubectl get pods -o wide # List all pods in the current namespace, with more details
kubectl get deployment my-dep # List a particular deployment
kubectl get pods # List all pods in the namespace
kubectl get pod my-pod -o yaml # Get a pod's YAML
# Describe commands with verbose output
kubectl describe nodes my-node
kubectl describe pods my-pod
# List Services Sorted by Name
kubectl get services --sort-by=.metadata.name
# List pods Sorted by Restart Count
kubectl get pods --sort-by='.status.containerStatuses[0].restartCount'
# List PersistentVolumes sorted by capacity
kubectl get pv --sort-by=.spec.capacity.storage
# Get the version label of all pods with label app=cassandra
kubectl get pods --selector=app=cassandra -o
jsonpath='{.items[*].metadata.labels.version}'
# Retrieve the value of a key with dots, e.g. 'ca.crt'
kubectl get configmap myconfig
-o jsonpath='{.data.ca.crt}'
# Get all worker nodes (use a selector to exclude results that have a label
# named 'node-role.kubernetes.io/master')
kubectl get node --selector='!node-role.kubernetes.io/master'
# Get all running pods in the namespace
kubectl get pods --field-selector=status.phase=Running
# Get ExternalIPs of all nodes
kubectl get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="ExternalIP")].address}'
# List Names of Pods that belong to Particular RC
# "jq" command useful for transformations that are too complex for jsonpath, it can be found at https://stedolan.github.io/jq/
sel=${$(kubectl get rc my-rc --output=json | jq -j '.spec.selector | to_entries | .[] | "(.key)=(.value),"')
echo $(kubectl get pods --selector=$sel --output=jsonpath={.items..metadata.name})
# Show labels for all pods (or any other Kubernetes object that supports labelling)
kubectl get pods --show-labels
# Check which nodes are ready
JSONPATH='{range .items[*]}{@.metadata.name}:{range @.status.conditions[*]}{@.type}={@.status};{end}{end}'
&& kubectl get nodes -o jsonpath="$JSONPATH" | grep "Ready=True"
# List all Secrets currently in use by a pod
kubectl get pods -o json | jq '.items[].spec.containers[].env[]?.valueFrom.secretKeyRef.name' | grep -v null | sort | uniq
# List all containerIDs of initContainer of all pods
# Helpful when cleaning up stopped containers, while avoiding removal of initContainers.
kubectl get pods --all-namespaces -o jsonpath='{range .items[*].status.initContainerStatuses[*]}{.containerID}{"n"}{end}' | cut -d/ -f3
# List Events sorted by timestamp
kubectl get events --sort-by=.metadata.creationTimestamp
# Compares the current state of the cluster against the state that the cluster would be in if the manifest was applied.
kubectl diff -f ./my-manifest.yaml
# Produce a period-delimited tree of all keys returned for nodes
# Helpful when locating a key within a complex nested JSON structure
kubectl get nodes -o json | jq -c 'path(..)|[.[]|tostring]|join(".")'
# Produce a period-delimited tree of all keys returned for pods, etc
kubectl get pods -o json | jq -c 'path(..)|[.[]|tostring]|join(".")'
Updating resources
kubectl set image deployment/frontend www=image:v2 # Rolling update "www" containers of "frontend" deployment, updating the image
kubectl rollout history deployment/frontend # Check the history of deployments including the revision
kubectl rollout undo deployment/frontend # Rollback to the previous deployment
kubectl rollout undo deployment/frontend --to-revision=2 # Rollback to a specific revision
kubectl rollout status -w deployment/frontend # Watch rolling update status of "frontend" deployment until completion
kubectl rollout restart deployment/frontend # Rolling restart of the "frontend" deployment
cat pod.json | kubectl replace -f - # Replace a pod based on the JSON passed into std
# Force replace, delete and then re-create the resource. Will cause a service outage.
kubectl replace --force -f ./pod.json
# Create a service for a replicated nginx, which serves on port 80 and connects to the containers on port 8000
kubectl expose rc nginx --port=80 --target-port=8000
# Update a single-container pod's image version (tag) to v4
kubectl get pod mypod -o yaml | sed 's/(image: myimage):.*$/1:v4/' | kubectl replace -f -
kubectl label pods my-pod new-label=awesome # Add a Label
kubectl annotate pods my-pod icon-url=http://goo.gl/XXBTWq # Add an annotation
kubectl autoscale deployment foo --min=2 --max=10 # Auto scale a deployment "foo"
Patching resources
# Partially update a node
kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}'
# Update a container's image; spec.containers[*].name is required because it's a merge key
kubectl patch pod valid-pod -p '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}'
# Update a container's image using a json patch with positional arrays
kubectl patch pod valid-pod --type='json' -p='[{"op": "replace", "path": "/spec/containers/0/image", "value":"new image"}]'
# Disable a deployment livenessProbe using a json patch with positional arrays
kubectl patch deployment valid-deployment --type json -p='[{"op": "remove", "path": "/spec/template/spec/containers/0/livenessProbe"}]'
# Add a new element to a positional array
kubectl patch sa default --type='json' -p='[{"op": "add", "path": "/secrets/1", "value": {"name": "whatever" } }]'
Editing resources
Edit any API resource in your preferred editor.
kubectl edit svc/docker-registry # Edit the service named docker-registry
KUBE_EDITOR="nano" kubectl edit svc/docker-registry # Use an alternative editor
Scaling resources
kubectl scale --replicas=3 rs/foo # Scale a replicaset named 'foo' to 3
kubectl scale --replicas=3 -f foo.yaml # Scale a resource specified in "foo.yaml" to 3
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql # If the deployment named mysql's current size is 2, scale mysql to 3
kubectl scale --replicas=5 rc/foo rc/bar rc/baz # Scale multiple replication controllers
Deleting resources
kubectl delete -f ./pod.json # Delete a pod using the type and name specified in pod.json
kubectl delete pod,service baz foo # Delete pods and services with same names "baz" and "foo"
kubectl delete pods,services -l name=myLabel # Delete pods and services with label name=myLabel
kubectl -n my-ns delete pod,svc --all # Delete all pods and services in namespace my-ns,
# Delete all pods matching the awk pattern1 or pattern2
kubectl get pods -n mynamespace --no-headers=true | awk '/pattern1|pattern2/{print $1}' | xargs kubectl delete -n mynamespace pod
Interacting with running Pods
kubectl logs my-pod # dump pod logs (stdout)
kubectl logs -l name=myLabel # dump pod logs, with label name=myLabel (stdout)
kubectl logs my-pod --previous # dump pod logs (stdout) for a previous instantiation of a container
kubectl logs my-pod -c my-container # dump pod container logs (stdout, multi-container case)
kubectl logs -l name=myLabel -c my-container # dump pod logs, with label name=myLabel (stdout)
kubectl logs my-pod -c my-container --previous # dump pod container logs (stdout, multi-container case) for a previous instantiation of a container
kubectl logs -f my-pod # stream pod logs (stdout)
kubectl logs -f my-pod -c my-container # stream pod container logs (stdout, multi-container case)
kubectl logs -f -l name=myLabel --all-containers # stream all pods logs with label name=myLabel (stdout)
kubectl run -i --tty busybox --image=busybox -- sh # Run pod as interactive shell
kubectl run nginx --image=nginx -n
mynamespace # Run pod nginx in a specific namespace
kubectl run nginx --image=nginx # Run pod nginx and write its spec into a file called pod.yaml
--dry-run=client -o yaml > pod.yaml
kubectl attach my-pod -i # Attach to Running Container
kubectl port-forward my-pod 5000:6000 # Listen on port 5000 on the local machine and forward to port 6000 on my-pod
kubectl exec my-pod -- ls / # Run command in existing pod (1 container case)
kubectl exec --stdin --tty my-pod -- /bin/sh # Interactive shell access to a running pod (1 container case)
kubectl exec my-pod -c my-container -- ls / # Run command in existing pod (multi-container case)
kubectl top pod POD_NAME --containers # Show metrics for a given pod and its containers
Interacting with Nodes and cluster
kubectl cordon my-node # Mark my-node as unschedulable
kubectl drain my-node # Drain my-node in preparation for maintenance
kubectl uncordon my-node # Mark my-node as schedulable
kubectl top node my-node # Show metrics for a given node
kubectl cluster-info # Display addresses of the master and services
kubectl cluster-info dump # Dump current cluster state to stdout
kubectl cluster-info dump --output-directory=/path/to/cluster-state # Dump current cluster state to /path/to/cluster-state
# If a taint with that key and effect already exists, its value is replaced as specified.
kubectl taint nodes foo dedicated=special-user:NoSchedule
Resource types
List all supported resource types along with their shortnames, API group, whether they are namespaced, and Kind:
kubectl api-resources
Other operations for exploring API resources:
kubectl api-resources --namespaced=true # All namespaced resources
kubectl api-resources --namespaced=false # All non-namespaced resources
kubectl api-resources -o name # All resources with simple output (just the resource name)
kubectl api-resources -o wide # All resources with expanded (aka "wide") output
kubectl api-resources --verbs=list,get # All resources that support the "list" and "get" request verbs
kubectl api-resources --api-group=extensions # All resources in the "extensions" API group
Formatting output
To output details to your terminal window in a specific format, add the -o (or --output) flag to a supported kubectl command.
Output format
Description
-o=custom-columns=<spec>
Print a table using a comma separated list of custom columns
-o=custom-columns-file=<filename>
Print a table using the custom columns template in the <filename> file
Print the fields defined by the jsonpath expression in the <filename> file
-o=name
Print only the resource name and nothing else
-o=wide
Output in the plain-text format with any additional information, and for pods, the node name is included
-o=yaml
Output a YAML formatted API object
Examples using -o=custom-columns:
# All images running in a cluster
kubectl get pods -A -o=custom-columns='DATA:spec.containers[*].image'
# All images excluding "k8s.gcr.io/coredns:1.6.2"
kubectl get pods -A -o=custom-columns='DATA:spec.containers[?(@.image!="k8s.gcr.io/coredns:1.6.2")].image'
# All fields under metadata regardless of name
kubectl get pods -A -o=custom-columns='DATA:metadata.*'
Kubectl verbosity is controlled with the -v or --v flags followed by an integer representing the log level. General Kubernetes logging conventions and the associated log levels are described here.
Verbosity
Description
--v=0
Generally useful for this to always be visible to a cluster operator.
--v=1
A reasonable default log level if you don’t want verbosity.
--v=2
Useful steady state information about the service and important log messages that may correlate to significant changes in the system. This is the recommended default log level for most systems.
--v=3
Extended information about changes.
--v=4
Debug level verbosity.
--v=6
Display requested resources.
--v=7
Display HTTP request headers.
--v=8
Display HTTP request contents.
--v=9
Display HTTP request contents without truncation of contents.
Helm – The Kubernetes Package Manager – Home – Github Helm: package manager (analogous to yum and apt) Charts: packages (analogous to debs and rpms). Home for these Charts is the Kubernetes Charts repository.
Helm package. It contains all of the resource definitions necessary to run an application, tool, or service inside of a Kubernetes cluster.
Repository
Place where charts can be collected and shared.
Release
Instance of a chart running in a Kubernetes cluster. One chart can often be installed many times into the same cluster. And each time it is installed, a new release is created. Consider a MySQL chart. If you want two databases running in your cluster, you can install that chart twice. Each one will have its own release, which will in turn have its own release name.
- helm search: search for charts
- helm pull: download a chart to your local directory to view
- helm install: upload the chart to Kubernetes
- helm list: list releases of charts
Environment variables:
| Name | Description |
|------------------------------------|-----------------------------------------------------------------------------------|
| $HELM_CACHE_HOME | set an alternative location for storing cached files. |
| $HELM_CONFIG_HOME | set an alternative location for storing Helm configuration. |
| $HELM_DATA_HOME | set an alternative location for storing Helm data. |
| $HELM_DEBUG | indicate whether or not Helm is running in Debug mode |
| $HELM_DRIVER | set the backend storage driver. Values are: configmap, secret, memory, postgres |
| $HELM_DRIVER_SQL_CONNECTION_STRING | set the connection string the SQL storage driver should use. |
| $HELM_MAX_HISTORY | set the maximum number of helm release history. |
| $HELM_NAMESPACE | set the namespace used for the helm operations. |
| $HELM_NO_PLUGINS | disable plugins. Set HELM_NO_PLUGINS=1 to disable plugins. |
| $HELM_PLUGINS | set the path to the plugins directory |
| $HELM_REGISTRY_CONFIG | set the path to the registry config file. |
| $HELM_REPOSITORY_CACHE | set the path to the repository cache directory |
| $HELM_REPOSITORY_CONFIG | set the path to the repositories file. |
| $KUBECONFIG | set an alternative Kubernetes configuration file (default "~/.kube/config") |
| $HELM_KUBEAPISERVER | set the Kubernetes API Server Endpoint for authentication |
| $HELM_KUBEASGROUPS | set the Groups to use for impersonation using a comma-separated list. |
| $HELM_KUBEASUSER | set the Username to impersonate for the operation. |
| $HELM_KUBECONTEXT | set the name of the kubeconfig context. |
| $HELM_KUBETOKEN | set the Bearer KubeToken used for authentication. |
Helm stores cache, configuration, and data based on the following configuration order:
– If a HELM_*_HOME environment variable is set, it will be used – Otherwise, on systems supporting the XDG base directory specification, the XDG variables will be used – When no other location is set a default location will be used based on the operating system
By default, the default directories depend on the Operating System. The defaults are listed below:
| OS | Cache Path | Configuration Path | Data Path
|---------|---------------------------|--------------------------------|-------------------------|
| Linux | $HOME/.cache/helm | $HOME/.config/helm | $HOME/.local/share/helm
| macOS | $HOME/Library/Caches/helm | $HOME/Library/Preferences/helm | $HOME/Library/helm
| Windows |
Available Commands:
completion generate autocompletions script for the specified shell
create create a new chart with the given name
dependency manage a chart's dependencies
env helm client environment information
get download extended information of a named release
help Help about any command
history fetch release history
install install a chart
lint examine a chart for possible issues
list list releases
package package a chart directory into a chart archive
plugin install, list, or uninstall Helm plugins
pull download chart from repository and unpack in local directory
repo add, list, remove, update, and index chart repositories
rollback roll back a release to a previous revision
search search for a keyword in charts
show show information of a chart
status display the status of the named release
template locally render templates
test run tests for a release
uninstall uninstall a release
upgrade upgrade a release
verify verify that a chart at the given path has been signed and is valid
version print the client version information
Flags
--debug enable verbose output
-h, --help help for helm
--kube-apiserver string the address and the port for Kubernetes API server
--kube-as-group stringArray Group to impersonate for the operation,
flag can be repeated to specify multiple groups.
--kube-as-user string Username to impersonate for the operation
--kube-context string name of the kubeconfig context to use
--kube-token string bearer token used for authentication
--kubeconfig string path to the kubeconfig file
-n, --namespace string namespace scope for this request
--registry-config string path to the registry config file
(<User>\AppData\Roaming\helm\registry.json)
--repository-cache string path to file containing cached repository indexes
(<User>\AppData\Local\Temp\helm\repository)
--repository-config string path to file containing repository names and URLs
(<User>\AppData\Roaming\helm\repositories.yaml)
Use "helm [command] --help" for more information about a command.
Kubernetes : production-grade, open-source platform that orchestrates the placement (scheduling) and execution of application containers within and across computer clusters.
Deployment: responsible for creating and updating instances of your application
Pod: group of one or more application containers (such as Docker) and includes shared storage (volumes), IP address and information about how to run them.
Node: a worker machine in Kubernetes and may be either a virtual or a physical machine, depending on the cluster.Multiple Pods can run on one Node.
Kubernetes Service: abstraction layer which defines a logical set of Pods and enables external traffic exposure, load balancing and service discovery for those Pods.
Scaling is accomplished by changing the number of replicas in a Deployment
kubectl cluster-info
Kubernetes control plane is running at https://127.0.0.1:49153
KubeDNS is running at https://127.0.0.1:49153/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-minikube-6ddfcc9757-kpl5f 1/1 Running 1 5d22h
kubernetes-bootcamp-57978f5f5d-ccr6p 1/1 Running 0 6m25s
k
ubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{end}}'
> kubectl logs $PODNAME
Kubernetes Bootcamp App Started At: 2020-12-31T09:09:43.763Z | Running On: kubernetes-bootcamp-57978f5f5d-z8vsm
> kubectl exec $PODNAME env
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
HOSTNAME=kubernetes-bootcamp-57978f5f5d-z8vsm
KUBERNETES_PORT_443_TCP_PROTO=tcp
KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1
KUBERNETES_SERVICE_HOST=10.96.0.1
KUBERNETES_PORT_443_TCP_PORT=443
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_PORT=tcp://10.96.0.1:443
KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443
KUBERNETES_SERVICE_PORT=443
NPM_CONFIG_LOGLEVEL=info
NODE_VERSION=6.3.1
HOME=/root
> kubectl exec -ti $PODNAME bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@kubernetes-bootcamp-57978f5f5d-z8vsm:/# exit
exit
> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubernetes-bootcamp-57978f5f5d-z8vsm 1/1 Running 1 95m
❯ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6d
> kubectl get pods -l app=kubernetes-bootcamp
NAME READY STATUS RESTARTS AGE
kubernetes-bootcamp-57978f5f5d-z8vsm 1/1 Running 1 31h
> kubectl get services -l app=kubernetes-bootcamp
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-bootcamp NodePort 10.98.244.121 <none> 8080:31603/TCP 30h
> kubectl label pod $POD_NAME app=v1
error: 'app' already has a value (kubernetes-bootcamp), and --overwrite is false
❯ kubectl label pod $POD_NAME app=v1 --overwrite
pod/kubernetes-bootcamp-57978f5f5d-z8vsm labeled
> kubectl get pods -l app=v1
NAME READY STATUS RESTARTS AGE
kubernetes-bootcamp-57978f5f5d-z8vsm 1/1 Running 1 31h
Step 3: Deleting a service
> kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7d6h
kubernetes-bootcamp NodePort 10.98.244.121 <none> 8080:31603/TCP 30h
❯ kubectl delete service -l app=kubernetes-bootcamp
service "kubernetes-bootcamp" deleted
> kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
kubernetes-bootcamp 4/4 4 4 32h
❯ kubectl scale deployments/kubernetes-bootcamp --replicas=2
deployment.apps/kubernetes-bootcamp scaled
❯ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
kubernetes-bootcamp 2/2 2 2 32h
> kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kubernetes-bootcamp-57978f5f5d-9fwnz 1/1 Running 0 48m 172.17.0.6 minikube <none> <none>
kubernetes-bootcamp-57978f5f5d-wx9zg 1/1 Running 0 26m 172.17.0.7 minikube <none> <none>
kubernetes-bootcamp-57978f5f5d-z8vsm 1/1 Running 1 32h 172.17.0.5 minikube <none> <none>
docker ps — Lists running containers. Some useful flags include: -a / -all for all containers (default shows just running) and —-quiet /-q to list just their ids (useful for when you want to get all the containers).
docker pull — Most of your images will be created on top of a base image from the Docker Hub registry. Docker Hub contains many pre-built images that you can pull and try without needing to define and configure your own. To download a particular image, or set of images (i.e., a repository), use docker pull.
docker build — Builds Docker images from a Dockerfile and a “context”. A build’s context is the set of files located in the specified PATH or URL. Use the -t flag to label the image, for example docker build -t my_container . with the . at the end signalling to build using the currently directory.
docker logs — Display the logs of a container. You must specify a container and can use flags, such as --follow to follow the output in the logs of using the program. docker logs --follow my_container
docker volume ls — Lists the volumes,. Volumes are the preferred mechanism for persisting data generated by and used by Docker containers.
docker rm — Removes one or more containers. docker rm my_container
docker rmi — Removes one or more images. docker rmi my_image
docker stop — Stops one or more containers. docker stop my_containerstops one container, while docker stop $(docker ps -a -q) stops all running containers. A more direct way is to use docker kill my_container, which does not attempt to shut down the process gracefully first.
Use them together, for example to clean up all your docker images and containers:
kill all running containers with docker kill $(docker ps -q)
delete all stopped containers with docker rm $(docker ps -a -q)
delete all images with docker rmi $(docker images -q)
Create new container
Start a new docker image with a given name
You can start a new container by using the run command and specify the desired image
As a result, you are in the container at the bash command line
Reconnect to image
$ docker attach playground
Commit changes in container
$ docker start playground
$ docker attach playground
root@c106fbb48b20:/# echo 1.0 >VERSION
root@c106fbb48b20:/# exit
$ docker commit playground playground:1.0
$ docker tag playground:1.0 playground:latest
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
playground 1.0 01703597322b Less than a second ago 94.6MB
playground latest 01703597322b Less than a second ago 94.6MB
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
6742a11bff1e bridge bridge local
3af0a1c9eaac host host local
e60f68aad9d6 none null local
c97a80b449d9 playground_bridge bridge local
Start the database application using the bridges network
$ docker run -d --net=playground_bridge --name playground_db training/postgres
88abb9d018c628ed1abe7da0466289846a8342a28b2cbef3305ea5313c46d647
root@a5b411d609f0:/# uname -a
Linux a5b411d609f0 4.4.27-moby #1 SMP Wed Oct 26 14:21:29 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
root@a5b411d609f0:/# id
uid=0(root) gid=0(root) groups=0(root)
root@a5b411d609f0:/# hostname
a5b411d609f0
root@a5b411d609f0:/#
Leave image
root@a5b411d609f0:/# exit
exit
$
Show running images
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b01ba9bfef78 ubuntu "/bin/bash" 41 seconds ago Exited (0) 2 seconds ago ubuntu
Start image
$ docker start ubuntu
ubuntu
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b01ba9bfef78 ubuntu "/bin/bash" 2 minutes ago Up 1 seconds ubuntu
Attach to image, e.g. “enter” the image
Don’t forget to press enter after you entered the command do display the shell in the image again
$ docker attach ubuntu
root@b01ba9bfef78:/#
Working with Docker
$ docker run -it --name ubuntu ubuntu bash
You are in a terminal with ubuntu and can do whatever you like.
$ docker-machine create --driver=virtualbox default
$ docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
default - virtualbox Running tcp://192.168.99.100:2376 v1.12.2
virtualbox - virtualbox Stopped Unknown
Show environment of machine
$ docker-machine env
export DOCKER_TLS_VERIFY="1"
export DOCKER_HOST="tcp://192.168.99.100:2376"
export DOCKER_CERT_PATH="/Users/docker/.docker/machine/machines/default"
export DOCKER_MACHINE_NAME="default"
# Run this command to configure your shell:
# eval $(docker-machine env)
Stop machine
$ docker-machine stop default
Stopping "default"...
docker-Machine "default" was stopped.
Start machine
$ docker-machine start default
Starting "default"...
(default) Check network to re-create if needed...
(default) Waiting for an IP...
Machine "default" was started.
Waiting for SSH to be available...
Detecting the provisioner...
Started machines may have new IP addresses. You may need to re-run the docker-machine env command.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.