
Unveiling the Power of Whisper AI: Architecture and Practical Implementations

Introduction
Welcome to the fascinating world of Whisper AI, OpenAI’s groundbreaking speech recognition system. As we delve deeper into the digital age, the ability to accurately transcribe and understand human speech has become invaluable. From powering virtual assistants to enhancing accessibility in technology, speech-to-text solutions are reshaping our interaction with devices.
This article will explore the intricate architecture of Whisper AI, guide you through its usage via command line, Python, and even demonstrate how to integrate it into a Flask application.
Whether you’re a developer, a tech enthusiast, or simply curious, join me in unraveling the capabilities of this remarkable technology.
Section 1: Understanding Whisper AI
Whisper AI stands as a testament to the advancements in artificial intelligence, specifically in speech recognition. Developed by OpenAI, this system is designed not just to transcribe speech but to understand it, accommodating various accents, dialects, and even noisy backgrounds.
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
The development of Whisper AI marks a significant milestone, showcasing OpenAI’s commitment to pushing the boundaries of AI and machine learning. In a world where effective communication is key, Whisper AI is a step towards bridging gaps and making technology more accessible to all.
Section 2: The Architecture of Whisper AI
At the heart of Whisper AI lies a sophisticated neural network, likely based on the Transformer model, renowned for its effectiveness in processing sequential data like speech.
These models are trained on vast datasets, enabling the system to recognize and interpret a wide array of speech patterns. What sets Whisper AI apart is its multilingual capabilities, proficiently handling different languages and dialects.
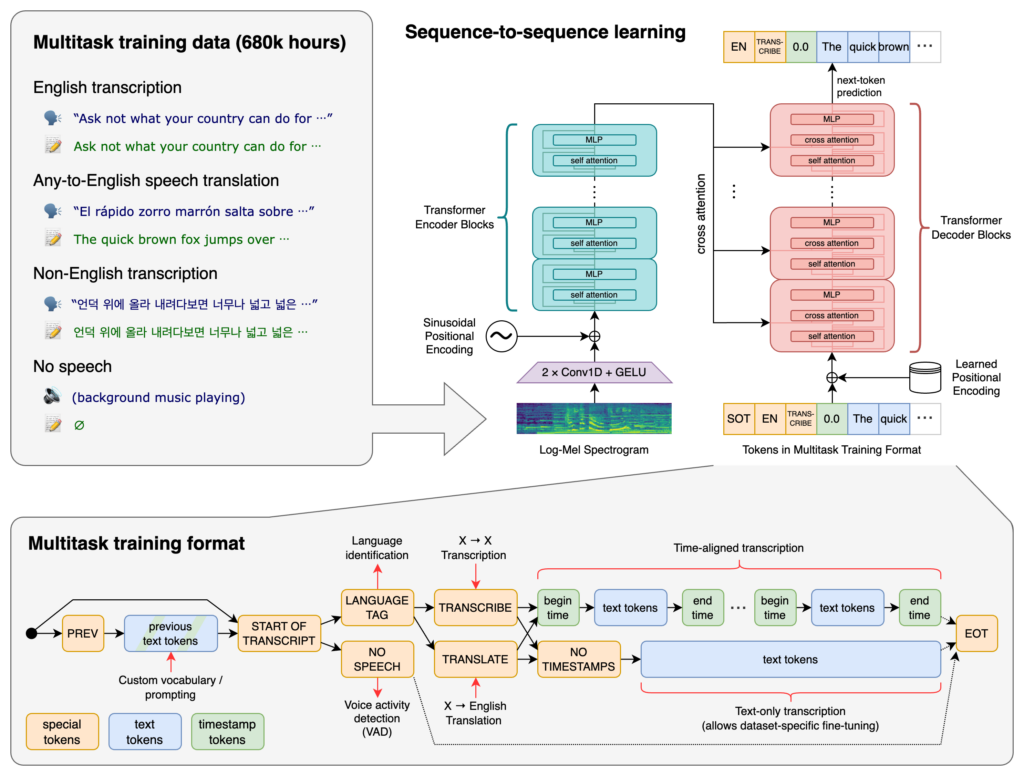
This architectural marvel not only enhances accuracy but also ensures inclusivity in speech recognition technology.
Section 3: Getting Started with Whisper AI
To embark on your journey with Whisper AI, a Python environment is a prerequisite. The system’s robustness requires adequate hardware specifications to function optimally.
Installation is straightforward: Whisper AI’s official documentation or https://github.com/openai/whisper provides comprehensive guides to get you started.
So, first: setup a python. virtual environment:
$ python -m venv venv $ . venv/bin/activate $ which python <Your current directoy>/venv/bin/python
Next step: install required tool for whisper:
$ sudo apt update && sudo apt install ffmpeg
And, at last: install whisper:
$ pip install git+https://github.com/openai/whisper.git
And your done.
Section 4: Using Whisper AI via Command Line
Whisper AI shines in its simplicity of use, particularly via the command line. After a basic setup, transcribing an audio file is as simple as running a command
For instance, whisper youraudiofile.mp3 could yield a text transcription of the recorded speech. This ease of use makes Whisper AI an attractive option for quick transcription tasks, and the command line interface provides a straightforward way for anyone to harness its power.
Run the following commmand to transcribe your audio file:
$ whisper <your audio file> --model medium --threads 16
See some samples in the following Section and in Section 9.
Section 5: Integrating Whisper AI with Python
Python enthusiasts can rejoice in the seamless integration of Whisper AI with Python scripts.
Imagine a script that takes an audio file and uses Whisper AI to transcribe it – this can be as concise as a few lines of code.
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])The API’s intuitive design means that with basic Python knowledge, you can create scripts to automate transcription tasks, analyze speech data, or even build more complex speech-to-text applications.
import whisper
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)Section 6: Building a Flask Application with Whisper AI
Integrating Whisper AI into a Flask application opens a realm of possibilities. A simple Flask server can receive audio files and return transcriptions, all powered by Whisper AI.
This setup is ideal for creating web applications that require speech-to-text capabilities. From voice-commanded actions to uploading and transcribing audio files, the combination of Flask and Whisper AI paves the way for innovative web-based speech recognition solutions.
Here is a short code for a flask app:
from flask import Flask, abort, request
from flask_cors import CORS
from tempfile import NamedTemporaryFile
import whisper
import torch
torch.cuda.is_available()
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
model = whisper.load_model("base", device=DEVICE)
app = Flask(__name__)
CORS(app)
@app.route("/")
def hello():
return "Whisper Hello World!"
@app.route('/whisper', methods=['POST'])
def handler():
if not request.files:
abort(400)
results = []
for filename, handle in request.files.items():
temp = NamedTemporaryFile()
handle.save(temp)
result = model.transcribe(temp.name)
results.append({
'filename': filename,
'transcript': result['text'],
})
return {'results': results}Section 7: Advanced Features and Customization
For those looking to push the boundaries, Whisper AI offers advanced features and customization options.
Adapting the system to recognize specific terminologies or accent nuances can significantly enhance its utility in specialized fields. This level of customization ensures that Whisper AI remains a versatile tool, adaptable to various professional and personal needs.
Section 8: Ethical Considerations and Limitations
As with any AI technology, Whisper AI brings with it ethical considerations.
The paramount concern is privacy and the security of data processed by the system. Additionally, while Whisper AI is a remarkable technology, it is not without limitations. Potential biases in language models and challenges in understanding heavily accented or distorted speech are areas that require ongoing refinement.
Addressing these concerns is crucial for the responsible development and deployment of speech recognition technologies.
Section 9: Samples
First, get your audio file to transcribed. I choose a famous speech from Abraham Lincoln and get it from Youtube.
$ yt-dlp -S res,ext:mp4:m4a "https://www.youtube.com/watch?v=bC4kQ2-kHZE" --output Abraham-Lincoln_Gettysburg-Address.mp4
Then, i use whisper to transcribe the audio.
$ whisper Abraham-Lincoln_Gettysburg-Address.mp4 --model medium --threads 16 --output_dir .
.../.venv/python/3.11/lib/python3.11/site-packages/whisper/transcribe.py:115: UserWarning: FP16 is not supported on CPU; using FP32 instead
warnings.warn("FP16 is not supported on CPU; using FP32 instead")
Detecting language using up to the first 30 seconds. Use `--language` to specify the language
Detected language: English
[00:00.000 --> 00:19.660] 4 score and 7 years ago, our fathers brought forth on this continent a new nation, conceived
[00:19.660 --> 00:28.280] in liberty and dedicated to the proposition that all men are created equal.
[00:28.280 --> 00:37.600] Now we are engaged in a great civil war, testing whether that nation, or any nation so conceived
[00:37.600 --> 00:43.680] and so dedicated, can long endure.
[00:43.680 --> 00:48.660] We are met on a great battlefield of that war.
[00:48.660 --> 00:54.800] We have come to dedicate a portion of that field as a final resting place for those who
[00:54.800 --> 00:59.840] here gave their lives that that nation might live.
[00:59.840 --> 01:09.600] It is altogether fitting and proper that we should do this, but in a larger sense, we
[01:09.600 --> 01:18.440] cannot dedicate, we cannot consecrate, we cannot hallow this ground.
[01:18.440 --> 01:25.720] The brave men, living and dead, who struggled here, have consecrated it, far above our
[01:25.720 --> 01:30.640] poor power to add or detract.
[01:30.640 --> 01:37.280] The world will little note, nor long remember what we say here, but it can never forget
[01:37.280 --> 01:40.040] what they did here.
[01:40.040 --> 01:47.440] It is for us, the living rather, to be dedicated here, to the unfinished work which they who
[01:47.440 --> 01:52.360] fought here have thus far so nobly advanced.
[01:52.360 --> 01:59.680] It is rather for us to be here dedicated to the great task remaining before us, that from
[01:59.680 --> 02:06.220] these honored dead we take increased devotion to that cause for which they gave the last
[02:06.220 --> 02:13.960] full measure of devotion, that we here highly resolve that these dead shall not have died
[02:13.960 --> 02:23.520] in vain, that this nation, under God, shall have a new birth of freedom, and that government
[02:23.520 --> 02:31.000] of the people, by the people, for the people, shall not perish from the earth.Conclusion
Whisper AI represents a significant leap in speech recognition technology. Its implications for the future of human-computer interaction are profound. As we continue to explore and expand the capabilities of AI, tools like Whisper AI not only enhance our present but also shape our future in technology.
I encourage you to explore Whisper AI, experiment with its features, and share your experiences. The journey of discovery is just beginning.
Just image, if AI is helping you in daily tasks, you have more free time for other things:



Additional Resources
For those eager to dive deeper, the Whisper AI documentation, available on OpenAI’s official website and GitHub, offers extensive information and tutorials. Community forums and discussions provide valuable insights and practical advice for both novice and experienced users.