Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types of computations which includes Interactive Queries and Stream Processing.
This is an extract from this brief tutorial that explains the basics of Spark Core programming.
When i downloaded the template from Github and examine the content, i find out, that for each component (Pricing, Service, Contact), there is a corresponding HTML-file with all the content and all the formatting code:
about.html
blog-home-1.html
blog-home-2.html
blog-post.html
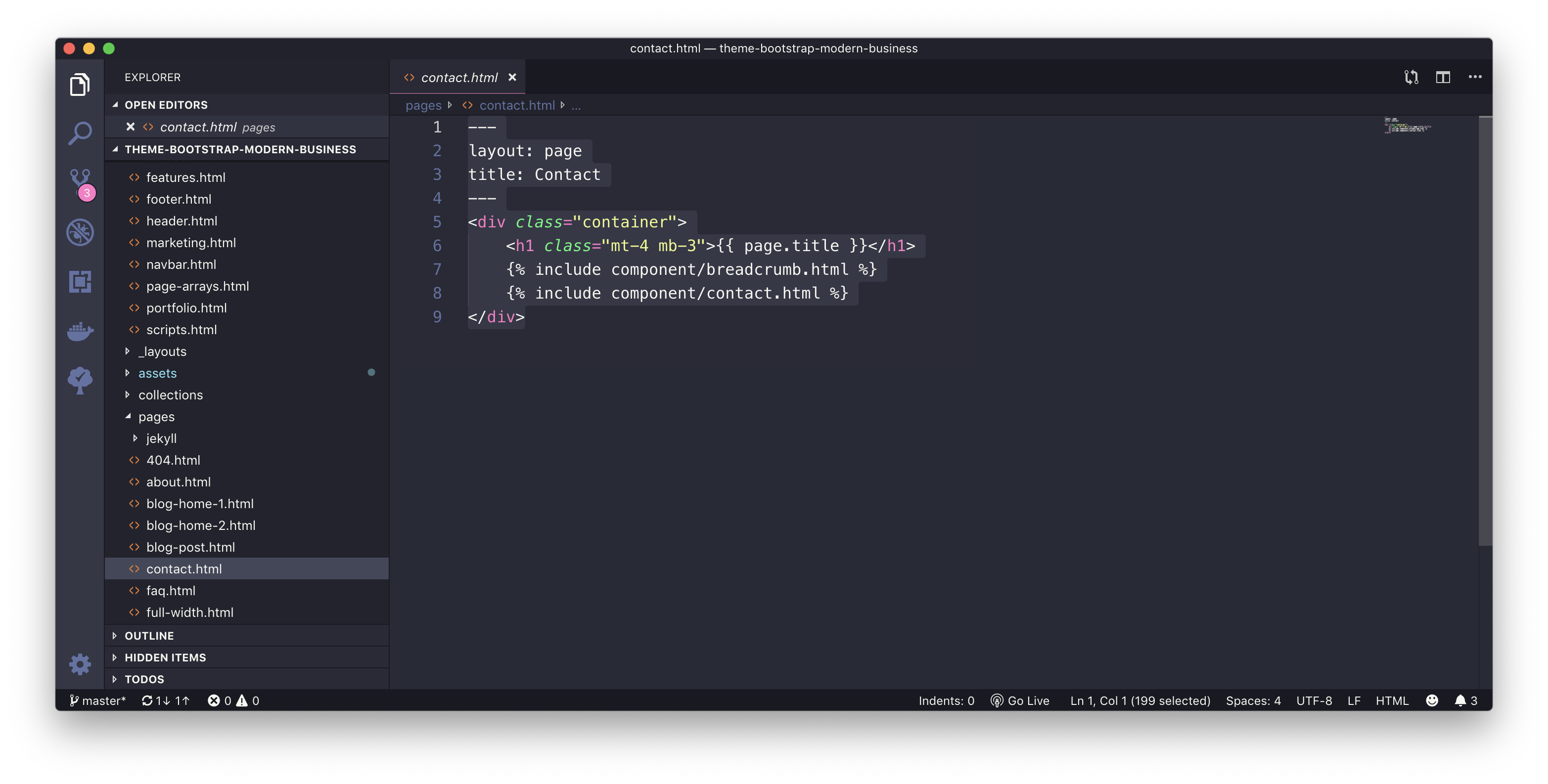
contact.html
faq.html
full-width.html
index.html
portfolio-1-col.html
portfolio-2-col.html
portfolio-3-col.html
portfolio-4-col.html
portfolio-item.html
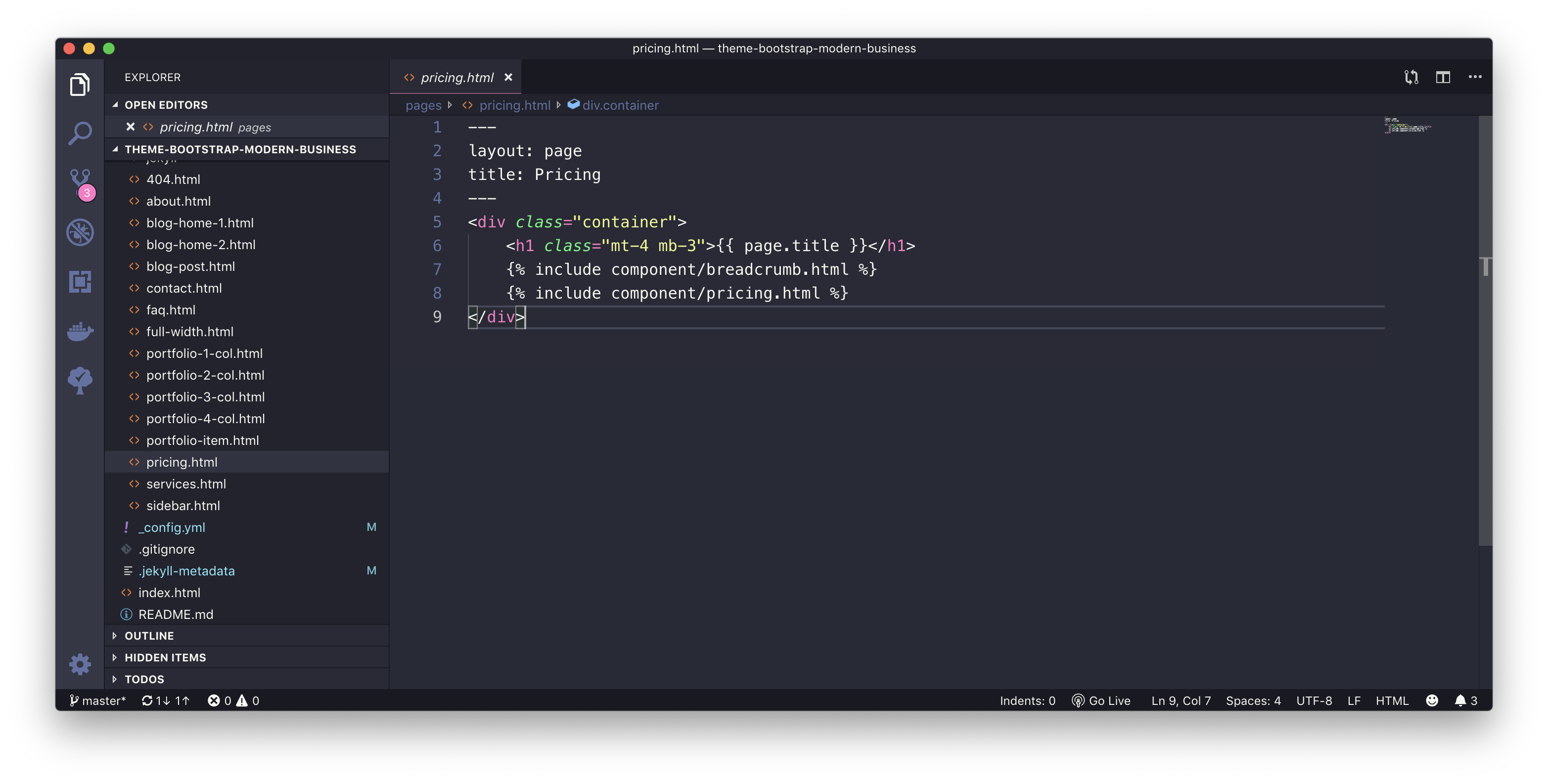
pricing.html
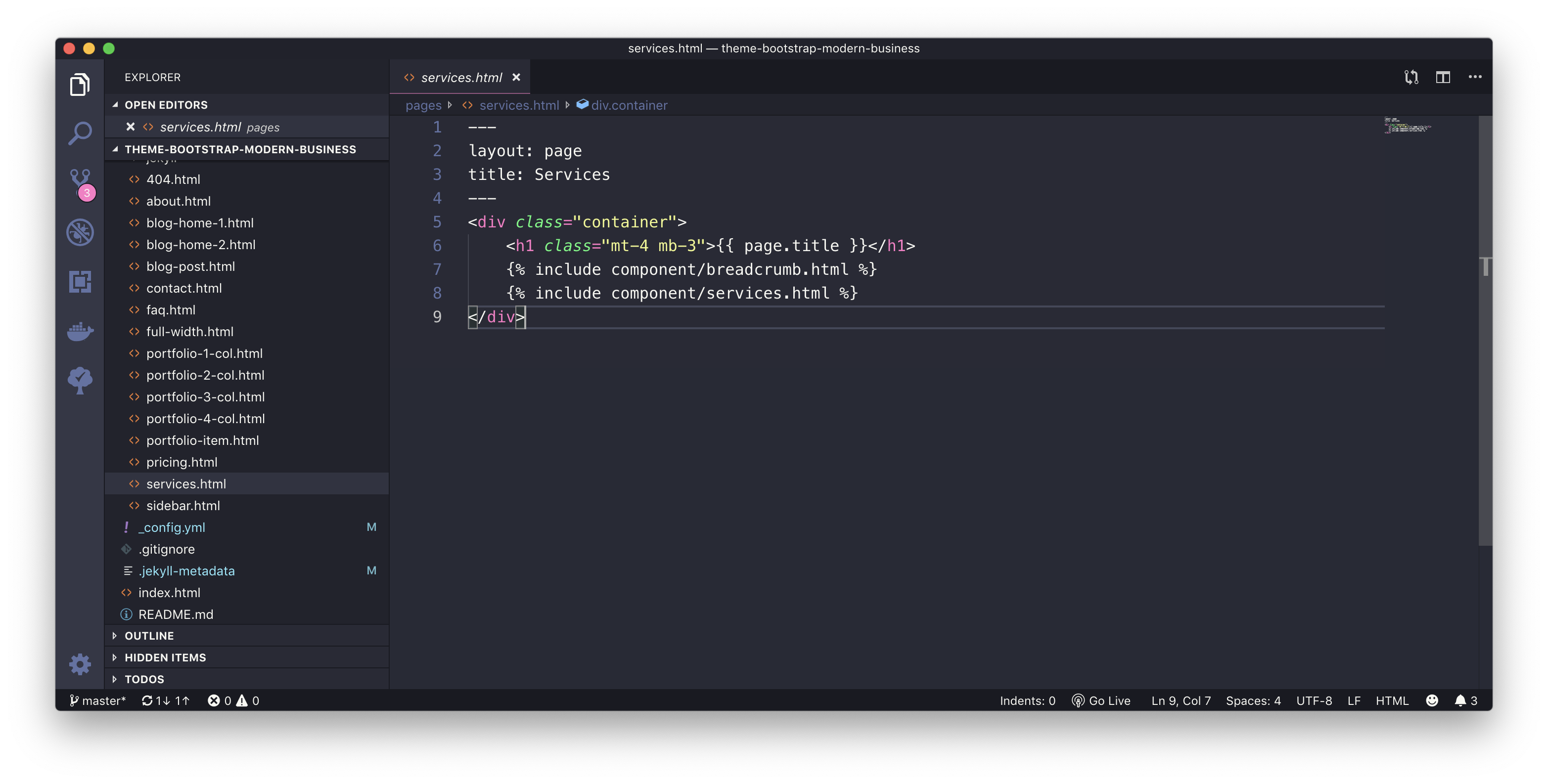
services.html
sidebar.html
The Plan
My plan was to separate the presentation layer (what you will see) from the business layer (what creates the content for the presentation layer).
To achieve this with Jekyll, i convert the Bootstrap pages to Jekyll include pages. The final result should look like this:
Next step was to convert every Bootstrap Template Page to a Jekyll Include File
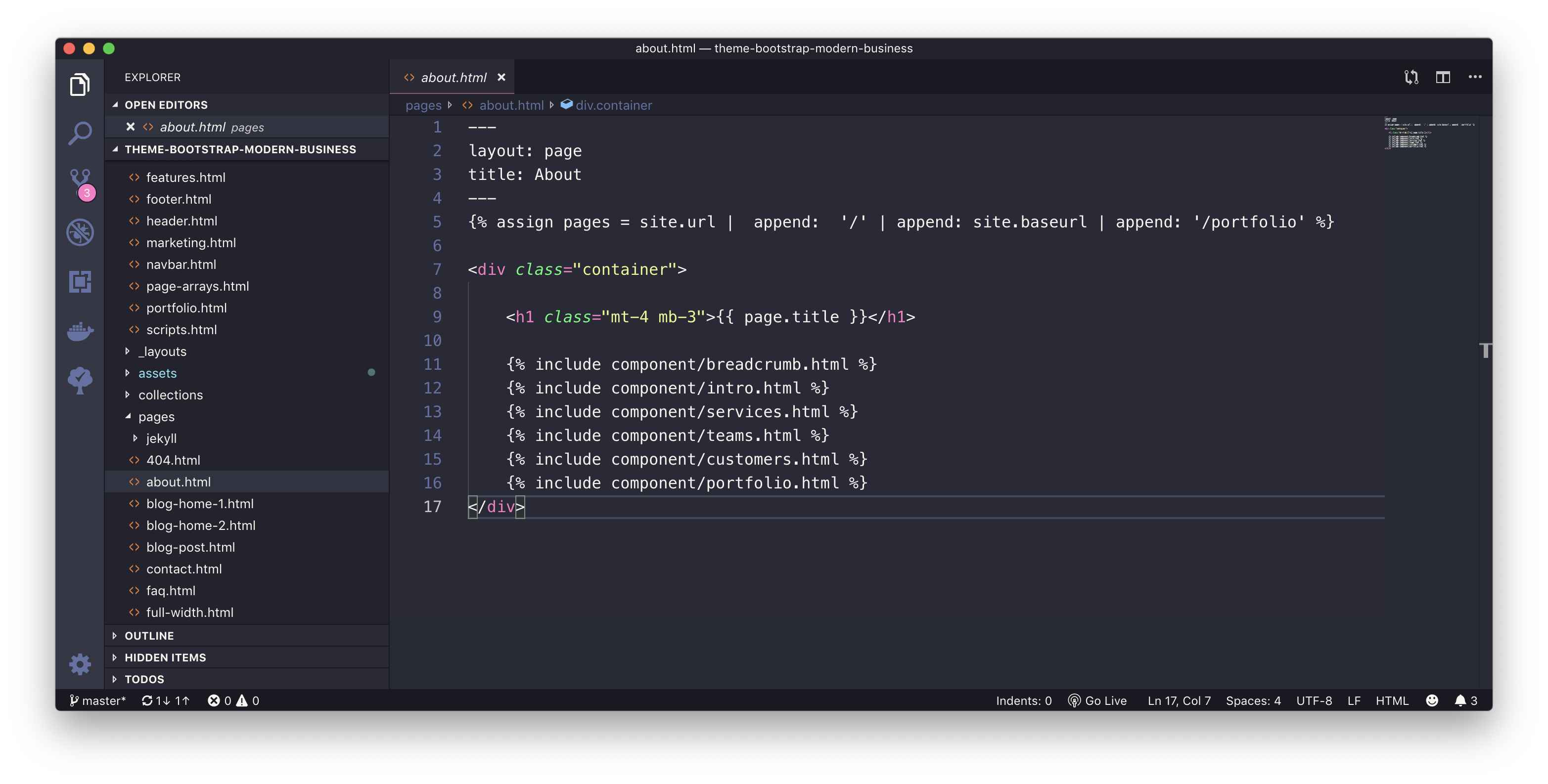
About Page
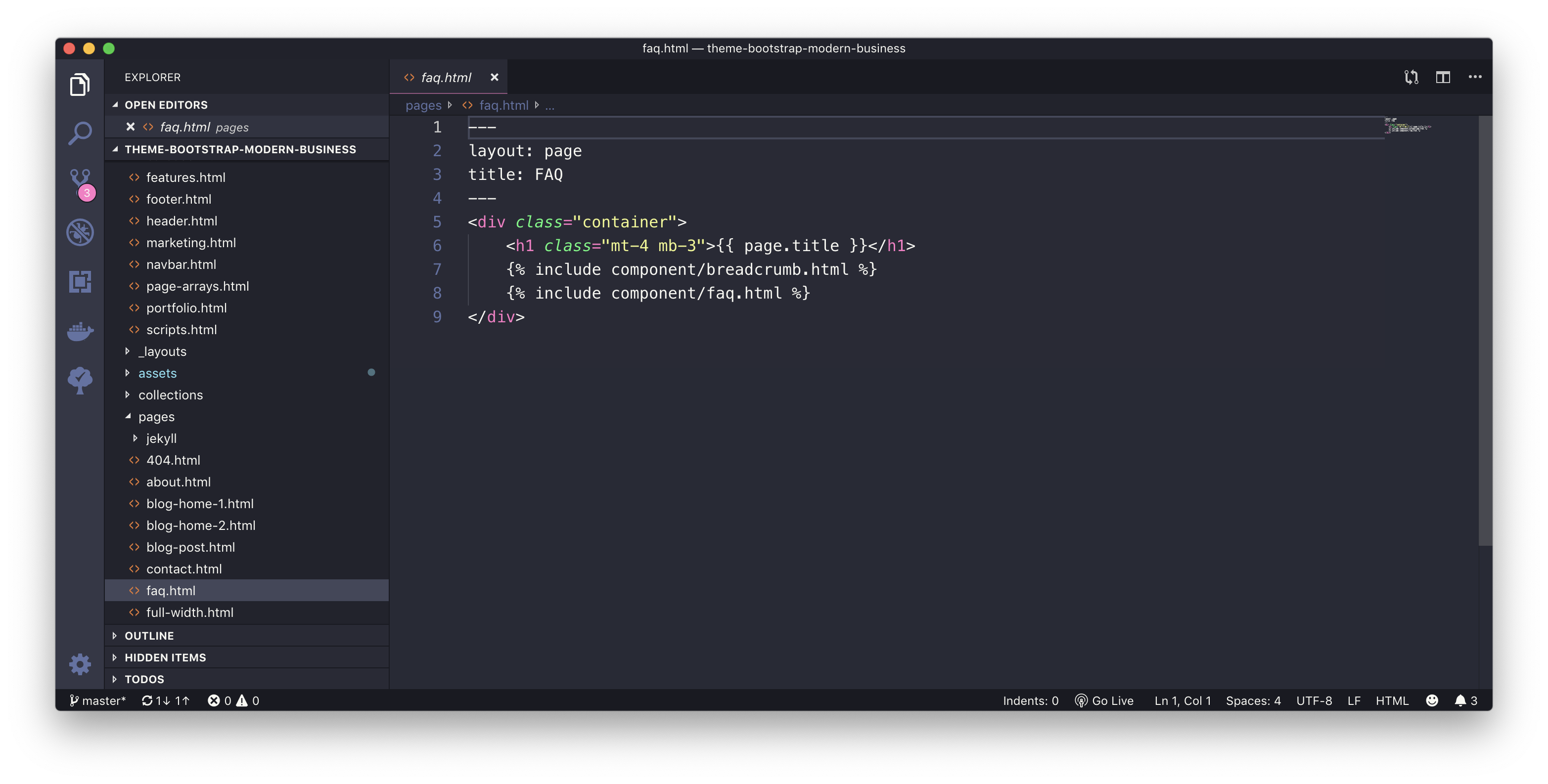
FAQ Page
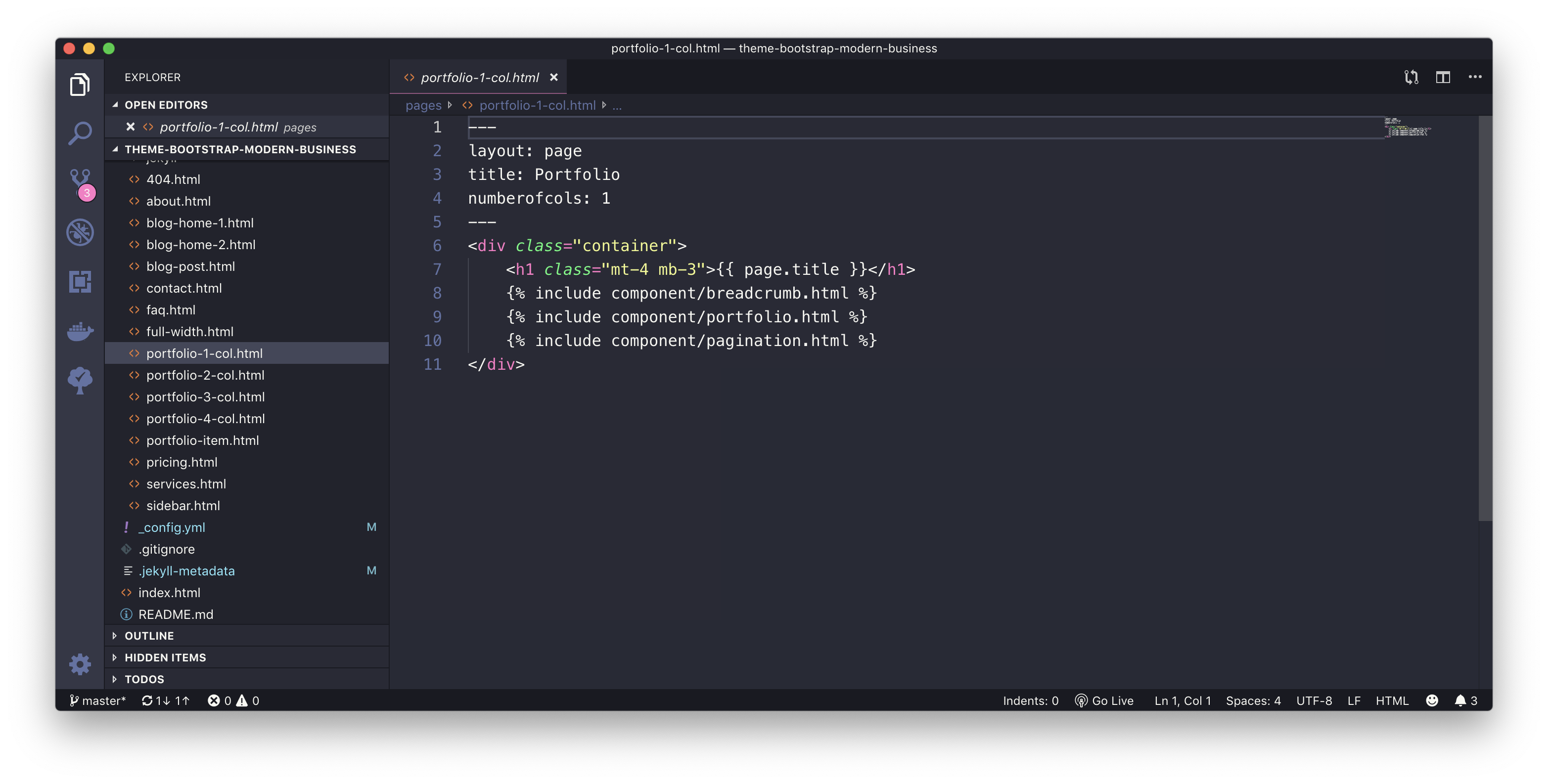
Portfolio Page with 1 Column
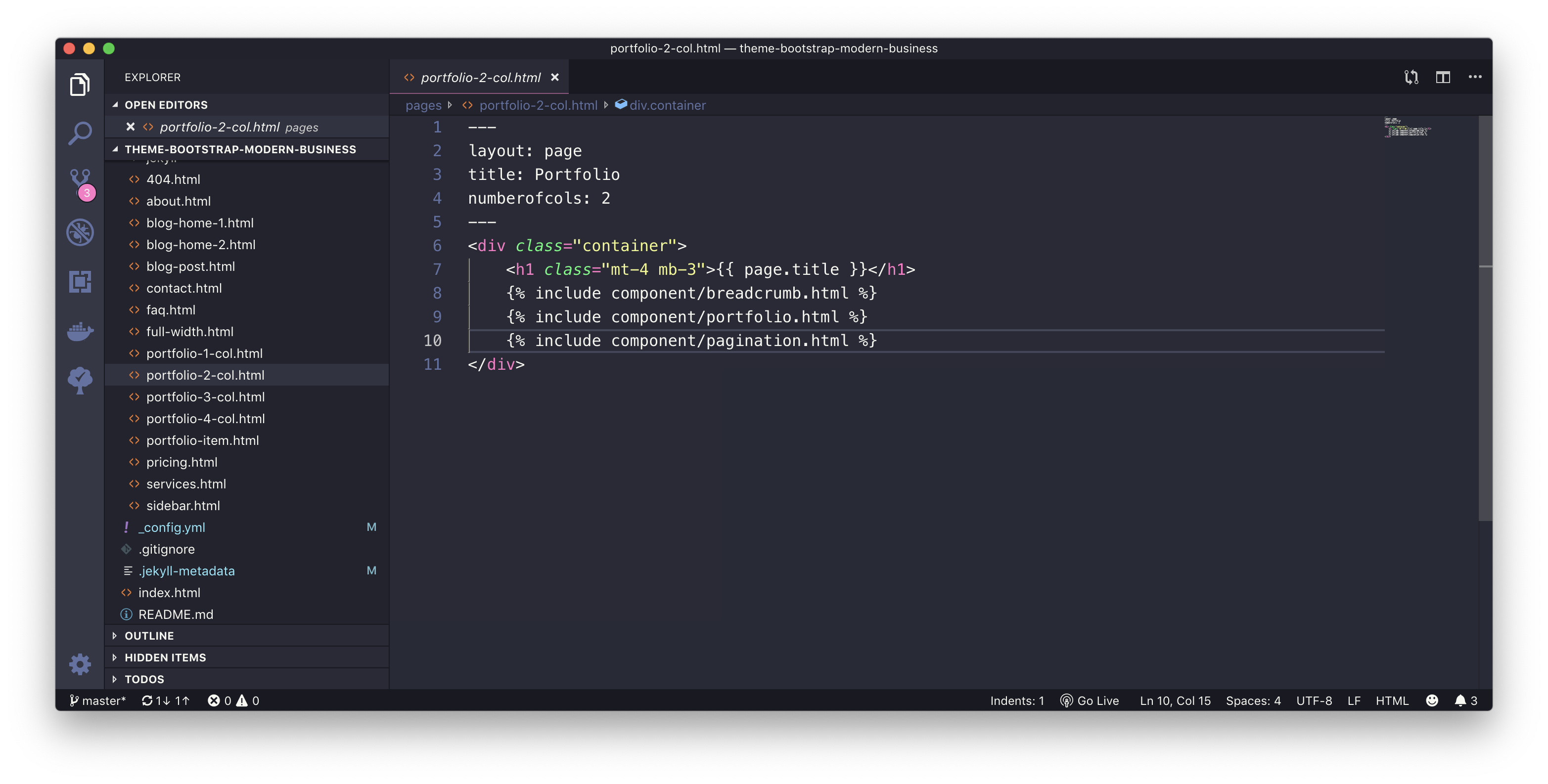
Portfolio Page with 2 Column
Services Page
Pricing Page
The main challenge in separating the presentation from the business layer was: where to place the data to be displayed?
Depending on the type of the component, i choose three different solutions:
Place the data in the corresponding include file of the component
Place the date in the page, which calls the corresponding include file of the component
Place the data in a Jekyll collection file
Data in corresponding include file of the component
I used this approach for components, which are used only once on the website and have a mostly static content, e.g. the FAQ Page
The component page
The frontend page
Date in the page, which calls the corresponding include file of the component
I used this approach for components, which are used more than once on the website, e.g. a Blog Post
The component page
The frontend page
Data in a Jekyll collection file
I used this approach for components, which are used only once on the website, but needs more configuration information, e.g. the Services- or Portfolio Page.
This step needs an additional configuration task: create the Jekyll Collections.
Jekyll collections are a great way to group related content like members of a team or talks at a conference.
To use a Collection you first need to define it in your _config.yml.
#
collections_dir: collections # folder, where collections files are stored
collections:
services:
title: "Services"
output: true # store output files for each item under the collections folder
Then, you have to create the collection files, for each item in your collection one file:
These files look like this:
---
img: 1.jpg
title: Development
subtitle:
footer:
text: Lorem ipsum dolor sit amet, consectetur adipisicing elit. Possimus aut mollitia eum ipsum fugiat odio officiis odit.
---
And the data of this files can be accessed in the Jekyll include file with this code fragment:
Dataflow scripting tool similar to a Batch job or simplistic ETL processer
Flume
Collector/Facilitator of Log file information
Ambari
Web-based Admin tool utilized for managing, provisioning, and monitoring Hadoop Cluster
Cassandra
High-Availability, Scalable, Multi-Master database platform…RDBMS on sterioids
Mahout
Machine Learning engine, which translates into, it does complex calculations, algorithmic processing, and statistical/stochastic operations using R and other frameworks…it does serious math!
Spark
Programmatic based compute engine allowing for ETL, machine learning, stream processing, and graph computation
ZooKeeper
Coordinator service for all your distributed processing
$ adb uninstall io.ionic.conference
$ ionic run android
Working on iOS
List available devices
$ ios-sim showdevicetypes
Run on Emulator
$ ionic emulate ios --target="iPhone-6, 10.1"
Run on Device
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.